- 推荐2
- 收藏11
- 浏览5.0K
Python与机器学习实战:决策树、集成学习、支持向量机与神经网络算法详解及编程实现
- 书 号:978-7-121-31720-0
- 出版日期:2017-06-30
- 页 数:328
- 开 本:16(185*235)
- 出版状态:上市销售
- 维护人:张月萍
纸质版 ¥69.00
Python与机器学习这一话题是如此的宽广,仅靠一本书自然不可能涵盖到方方面面,甚至即使出一个系列也难能做到这点。单就机器学习而言,其领域就包括但不限于如下:有监督学习(Supervised Learning),无监督学习(Unsupervised Learning)和半监督学习(Semi-Supervised Learning)。而具体的问题又大致可以分两类:分类问题(Classification)和回归问题(Regression)。
Python本身带有许多机器学习的第三方库,但本书在绝大多数情况下只会用到Numpy这个基础的科学计算库来进行算法代码的实现。这样做的目的是希望读者能够从实现的过程中更好地理解机器学习算法的细节,以及了解Numpy的各种应用。不过作为补充,本书会在适当的时候应用scikit-learn这个成熟的第三方库中的模型。
本书适用于想了解传统机器学习算法的学生和从业者,想知道如何高效实现机器的算法的程序员,以及想了解机器学习的算法能如何进行应用的职员、经理等。
Python本身带有许多机器学习的第三方库,但本书在绝大多数情况下只会用到Numpy这个基础的科学计算库来进行算法代码的实现。这样做的目的是希望读者能够从实现的过程中更好地理解机器学习算法的细节,以及了解Numpy的各种应用。不过作为补充,本书会在适当的时候应用scikit-learn这个成熟的第三方库中的模型。
本书适用于想了解传统机器学习算法的学生和从业者,想知道如何高效实现机器的算法的程序员,以及想了解机器学习的算法能如何进行应用的职员、经理等。
简单的Python,可以完成复杂的机器学习算法,跟我来吧!
前言
自从AlphaGo在2016年3月战胜人类围棋顶尖高手李世石后,“人工智能”“深度学习”这一类词汇就进入了大众的视野;而作为更加宽泛的一个概念——“机器学习”则多少顺势成为了从学术界到工业界都相当火热的话题。不少人可能都想尝试和体验一下“机器学习”这个可以说相当神奇的东西,不过可能又苦于不知如何下手。编著本书的目的,就是想介绍一种入门机器学习的方法。虽然市面上已经有许多机器学习的书籍,但它们大多要么过于偏重理论,要么过于偏重应用,要么过于“厚重”;本书致力于将理论与实践相结合,在讲述理论的同时,利用Python这一门简明有力的编程语言进行一系列的实践与应用。
当然,囿于作者水平,本书实现的一些模型从速度上来说会比成熟的第三方库中实现的模型要慢不少。一方面是因为比较好的第三方库背后往往会用底层语言来实现核心算法,另一方面则是本书通常会把数据预处理的过程涵盖在模型中。以决策树模型为例,scikit-learn中的决策树模型会比本书实现的要快很多,但本书实现的模型能够用scikit-learn中决策树模型训练不了的训练集来训练。
同时,限于篇幅、本书无法将所有代码都悉数放出(事实上这样做的意义也不是很大),所以我们会略去一些相对枯燥且和相应算法的核心思想关系不大的实现。对于这些实现,我们会进行相应的算法说明,感兴趣的读者可以尝试自己一步一步地去实现,也可以直接在GitHub上面查看笔者自己实现的版本(GitHub地址会在相应的地方贴出)。本书所涉及的所有代码都可以参见https://github.com/carefree0910/MachineLearning,笔者也建议在阅读本书之前先把这个链接里面的内容都下载下来作为参照。毕竟即使在本书收官之后,笔者仍然会不时地在上述链接中优化和更新相应的算法,而这些更新是无法反映在本书中的。
虽说确实可以完全罔顾理论来用机器学习解决许多问题,但是如果想要理解背后的道理并借此提高解决问题的效率,扎实的理论根基是必不可少的。本书会尽量避免罗列枯燥的数学公式,但是基本的公式常常不可或缺。虽然笔者想要尽量做到通俗易懂,但仍然还是需要读者拥有一定的数学知识。不过为了阅读体验良好,本书通常会将比较烦琐的数学理论及相关推导放在每一章的倒数第二节(最后一节是总结)作为某种意义上的“附加内容”。这样做有若干好处:
? 对于已经熟知相关理论的读者,可以不再重复地看同样的东西;
? 对于只想了解机器学习各种思想、算法和实现的读者,可以避免接受不必要的知识;
? 对于想了解机器学习背后道理和逻辑的读者,可以有一个集中的地方进行学习。
本书的特点
? 理论与实践结合,在较为详细、全面地讲解理论之后,会配上相应的代码实现以加深读者对相应算法的理解。
? 每一章都会有丰富的实例,让读者能够将本书所阐述的思想和模型应用到实际任务中。
? 在涵盖了诸多经典的机器学习算法的同时,也涵盖了许多最新的研究成果(比如最后一章所讲述的卷积神经网络(CNN)可以说就是许多“深度学习”的基础)。
? 所涉及的模型实现大多仅仅基于线性代数运算库(Numpy)而没有依赖更高级的第三方库,读者无须了解Python那浩如烟海的第三方库中的任何一个第三方库便能读懂本书的代码。
本书的内容安排
第1章 Python与机器学习入门
本章介绍了机器学习的概念和一些基础术语,比如泛化能力、过拟合、经验风险(ERM)和结构风险(SRM)等,还介绍了如何安装并使用Anaconda这一Python的科学运算环境。同时在最后,我们解决了一个小型的机器学习问题。本章内容虽不算多,却可说是本书所有内容的根基。
第2章 贝叶斯分类器
作为和我们比较熟悉的频率学派相异的学派,贝叶斯学派的思想相当耐人寻味,值得进行研究与体会。本章将主要介绍的朴素贝叶斯正是贝叶斯决策的一个经典应用,虽然它加了很强的假设,但其在实际应用中的表现仍然相当优异(比如自然语言处理中的文本分类)。而为了克服朴素贝叶斯假设过强的缺点,本章将简要介绍的,诸如半朴素贝叶斯和贝叶斯网这些贝叶斯分类器会在某些领域拥有更好的性能。
第3章 决策树
决策树可以说是最直观的机器学习模型之一,它多多少少拥有着信息论的一些理论背景作为支撑。决策树的训练思想简洁,模型本身可解读性强,本章将会在介绍其生成、剪枝等一系列实现的同时,通过一些可视化来对其有更好的理解。
第4章 集成学习
正所谓“三个臭皮匠,赛过诸葛亮”。集成学习的两大板块“Bootstrap”和“Boosting”所对应的主流模型——“随机森林(RandomForest)”和“AdaBoost”正是这句俗语的最佳解释。本章在介绍相关理论与实现的同时,将会通过相当多的例子来剖析集成学习的一些性质。
第5章 支持向量机
支持向量机(SVM)有着非常辉煌的历史,它背后那套相当深刻而成熟的数学理论让它在现代的深度学习中“异军突起”之前,占据着相当重要的地位。本章将会尽量厘清支持向量机的思想与相关的比较简明的理论,同时会通过一些对比来体现支持向量机的优异之处。
第6章 神经网络
神经网络在近现代可以说已经成为“耳熟能详”的词汇了,它让不少初次听说其名号的人(包括笔者在内)对其充满着各种幻想。虽说神经网络算法的推导看上去烦复而“令人生畏”,但其实所用到的知识都并不深奥。本章会相当详细地介绍神经网络中的两大算法——“前向传导算法”和“反向传播算法”,同时还会介绍诸多主流的“参数更新方法”。除此之外,本章还会提及如何在“大数据”下改进和优化我们的神经网络模型(这一套思想是可以推广到其他机器学习模型上的)。
第7章 卷积神经网络
卷积神经网络是许多深度学习的基础结构,它可以算是神经网络的一种拓展。卷积神经网络的思想具有很好的生物学直观,适合处理结构性的数据。同时,利用成熟的卷积神经网络模型,我们能够比较好地完成许多具有一定难度而相当有趣的任务;本章则会针对这些任务中的“图像分类”任务,提出一套比较详细的解决方案。
本书由浅入深,理论与实践并存,同时更是将理论也进行了合理的分级;无论在此前对机器学习有何种程度的认知,想必都能通过不同的阅读方式有所收获吧。
适合阅读本书的读者
? 想要了解某些传统机器学习算法细节的学生、老师、从业者等。
? 想要知道如何“从零开始”高效实现机器学习算法的程序员。
? 想要了解机器学习算法能如何进行应用的职员、经理等。
? 对机器学习抱有兴趣并想要入门的爱好者。
编者 何宇健
自从AlphaGo在2016年3月战胜人类围棋顶尖高手李世石后,“人工智能”“深度学习”这一类词汇就进入了大众的视野;而作为更加宽泛的一个概念——“机器学习”则多少顺势成为了从学术界到工业界都相当火热的话题。不少人可能都想尝试和体验一下“机器学习”这个可以说相当神奇的东西,不过可能又苦于不知如何下手。编著本书的目的,就是想介绍一种入门机器学习的方法。虽然市面上已经有许多机器学习的书籍,但它们大多要么过于偏重理论,要么过于偏重应用,要么过于“厚重”;本书致力于将理论与实践相结合,在讲述理论的同时,利用Python这一门简明有力的编程语言进行一系列的实践与应用。
当然,囿于作者水平,本书实现的一些模型从速度上来说会比成熟的第三方库中实现的模型要慢不少。一方面是因为比较好的第三方库背后往往会用底层语言来实现核心算法,另一方面则是本书通常会把数据预处理的过程涵盖在模型中。以决策树模型为例,scikit-learn中的决策树模型会比本书实现的要快很多,但本书实现的模型能够用scikit-learn中决策树模型训练不了的训练集来训练。
同时,限于篇幅、本书无法将所有代码都悉数放出(事实上这样做的意义也不是很大),所以我们会略去一些相对枯燥且和相应算法的核心思想关系不大的实现。对于这些实现,我们会进行相应的算法说明,感兴趣的读者可以尝试自己一步一步地去实现,也可以直接在GitHub上面查看笔者自己实现的版本(GitHub地址会在相应的地方贴出)。本书所涉及的所有代码都可以参见https://github.com/carefree0910/MachineLearning,笔者也建议在阅读本书之前先把这个链接里面的内容都下载下来作为参照。毕竟即使在本书收官之后,笔者仍然会不时地在上述链接中优化和更新相应的算法,而这些更新是无法反映在本书中的。
虽说确实可以完全罔顾理论来用机器学习解决许多问题,但是如果想要理解背后的道理并借此提高解决问题的效率,扎实的理论根基是必不可少的。本书会尽量避免罗列枯燥的数学公式,但是基本的公式常常不可或缺。虽然笔者想要尽量做到通俗易懂,但仍然还是需要读者拥有一定的数学知识。不过为了阅读体验良好,本书通常会将比较烦琐的数学理论及相关推导放在每一章的倒数第二节(最后一节是总结)作为某种意义上的“附加内容”。这样做有若干好处:
? 对于已经熟知相关理论的读者,可以不再重复地看同样的东西;
? 对于只想了解机器学习各种思想、算法和实现的读者,可以避免接受不必要的知识;
? 对于想了解机器学习背后道理和逻辑的读者,可以有一个集中的地方进行学习。
本书的特点
? 理论与实践结合,在较为详细、全面地讲解理论之后,会配上相应的代码实现以加深读者对相应算法的理解。
? 每一章都会有丰富的实例,让读者能够将本书所阐述的思想和模型应用到实际任务中。
? 在涵盖了诸多经典的机器学习算法的同时,也涵盖了许多最新的研究成果(比如最后一章所讲述的卷积神经网络(CNN)可以说就是许多“深度学习”的基础)。
? 所涉及的模型实现大多仅仅基于线性代数运算库(Numpy)而没有依赖更高级的第三方库,读者无须了解Python那浩如烟海的第三方库中的任何一个第三方库便能读懂本书的代码。
本书的内容安排
第1章 Python与机器学习入门
本章介绍了机器学习的概念和一些基础术语,比如泛化能力、过拟合、经验风险(ERM)和结构风险(SRM)等,还介绍了如何安装并使用Anaconda这一Python的科学运算环境。同时在最后,我们解决了一个小型的机器学习问题。本章内容虽不算多,却可说是本书所有内容的根基。
第2章 贝叶斯分类器
作为和我们比较熟悉的频率学派相异的学派,贝叶斯学派的思想相当耐人寻味,值得进行研究与体会。本章将主要介绍的朴素贝叶斯正是贝叶斯决策的一个经典应用,虽然它加了很强的假设,但其在实际应用中的表现仍然相当优异(比如自然语言处理中的文本分类)。而为了克服朴素贝叶斯假设过强的缺点,本章将简要介绍的,诸如半朴素贝叶斯和贝叶斯网这些贝叶斯分类器会在某些领域拥有更好的性能。
第3章 决策树
决策树可以说是最直观的机器学习模型之一,它多多少少拥有着信息论的一些理论背景作为支撑。决策树的训练思想简洁,模型本身可解读性强,本章将会在介绍其生成、剪枝等一系列实现的同时,通过一些可视化来对其有更好的理解。
第4章 集成学习
正所谓“三个臭皮匠,赛过诸葛亮”。集成学习的两大板块“Bootstrap”和“Boosting”所对应的主流模型——“随机森林(RandomForest)”和“AdaBoost”正是这句俗语的最佳解释。本章在介绍相关理论与实现的同时,将会通过相当多的例子来剖析集成学习的一些性质。
第5章 支持向量机
支持向量机(SVM)有着非常辉煌的历史,它背后那套相当深刻而成熟的数学理论让它在现代的深度学习中“异军突起”之前,占据着相当重要的地位。本章将会尽量厘清支持向量机的思想与相关的比较简明的理论,同时会通过一些对比来体现支持向量机的优异之处。
第6章 神经网络
神经网络在近现代可以说已经成为“耳熟能详”的词汇了,它让不少初次听说其名号的人(包括笔者在内)对其充满着各种幻想。虽说神经网络算法的推导看上去烦复而“令人生畏”,但其实所用到的知识都并不深奥。本章会相当详细地介绍神经网络中的两大算法——“前向传导算法”和“反向传播算法”,同时还会介绍诸多主流的“参数更新方法”。除此之外,本章还会提及如何在“大数据”下改进和优化我们的神经网络模型(这一套思想是可以推广到其他机器学习模型上的)。
第7章 卷积神经网络
卷积神经网络是许多深度学习的基础结构,它可以算是神经网络的一种拓展。卷积神经网络的思想具有很好的生物学直观,适合处理结构性的数据。同时,利用成熟的卷积神经网络模型,我们能够比较好地完成许多具有一定难度而相当有趣的任务;本章则会针对这些任务中的“图像分类”任务,提出一套比较详细的解决方案。
本书由浅入深,理论与实践并存,同时更是将理论也进行了合理的分级;无论在此前对机器学习有何种程度的认知,想必都能通过不同的阅读方式有所收获吧。
适合阅读本书的读者
? 想要了解某些传统机器学习算法细节的学生、老师、从业者等。
? 想要知道如何“从零开始”高效实现机器学习算法的程序员。
? 想要了解机器学习算法能如何进行应用的职员、经理等。
? 对机器学习抱有兴趣并想要入门的爱好者。
编者 何宇健
推荐用户
相关图书
虚拟现实宝典:以人为本的VR设计
全面系统深入的介绍虚拟现实的理论与实践。侧重于交互设计。而交互是VR开发中相当重要的一环。内容全面,包括了VR的简史,体感设计、内容设计、交互设计以及可能的负面...
集成学习:基础与算法
集成学习方法是一类先进的机器学习方法,这类方法训练多个学习器并将它们结合起来解决一个问题,在实践中获得了巨大成功。<br>全书分为三部分。第一部分主要介绍集成学...
¥89.00
深度学习核心技术与实践
本书主要介绍深度学习的核心算法,以及在计算机视觉、语音识别、自然语言处理中的相关应用。本书的作者们都是业界第一线的深度学习从业者,所以书中所写内容和业界联系紧密...
¥79.00
Java微服务实战
本书分为三部分:基础框架篇(1~6章)、服务框架篇(7~10章)、监控部署篇(11~13章),由浅入深来讲解微服务的相关技术。基础框架篇从微服务架构的基本概念与...
¥39.00
深度学习入门之PyTorch
深度学习如今已经成为了科技领域最炙手可热的技术,在本书中,我们将帮助你入门深度学习的领域。本书将从人工智能的介绍入手,了解机器学习和深度学习的基础理论,并学习如...
¥49.00
请问这本书有配套视频吗?麻烦分享一下,谢谢了
老师,您好,第71页下方计算式的下角标是否有误呢?
第32面关于离散型朴素贝叶斯的实现代码中,利用转换字典更新训练集的代码有误。
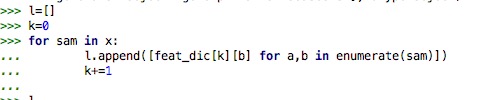
feat_dic[a][b]中的b和后面的b是同一个变量,但a不同,应该再定义一个变量k=0
,随着遍历k+=1,放入feat_dic[k][b]
第26页的p^hat(爆炸)= p(…) p(…) p(…)这一步看不懂,这是什么意思;等式左边的是先验概率,即 p(theta)?
git**ub上下载不了数据集