知识图谱是较为典型的多学科交叉领域,涉及知识工程、自然语言处理、机器学习、图数据库等多个领域。本书系统地介绍知识图谱涉及的关键技术,如知识建模、关系抽取、图存储、自动推理、图谱表示学习、语义搜索、知识问答、图挖掘分析等。此外,本书还尝试将学术前沿和实战结合,让读者在掌握实际应用能力的同时对前沿技术发展有所了解。
本书既适合计算机和人工智能相关的研究人员阅读,又适合在企业一线从事技术和应用开发的人员学习,还可作为高等院校计算机或人工智能专业师生的参考教材。
本书既适合计算机和人工智能相关的研究人员阅读,又适合在企业一线从事技术和应用开发的人员学习,还可作为高等院校计算机或人工智能专业师生的参考教材。
揭秘知识图谱全生命周期技术,探索垂直领域知识图谱构建方法与应用落地,促进人工智能从感知时代向认知时代跨越
前言
知识图谱的早期理念源于万维网之父Tim Berners-Lee关于语义网(The Semantic Web)的设想,旨在采用图结构(Graph Structure)来建模和记录世界万物之间的关联关系和知识,以便有效实现更加精准的对象级搜索。知识图谱的相关技术已经在搜索引擎、智能问答、语言理解、推荐计算、大数据决策分析等众多领域得到广泛的实际应用。近年来,随着自然语言处理、深度学习、图数据处理等众多领域的飞速发展,知识图谱在自动化知识获取、知识表示学习与推理、大规模图挖掘与分析等领域又取得了很多新进展。知识图谱已经成为实现认知层面的人工智能不可或缺的重要技术之一。
为什么写作本书
知识图谱是较为典型的交叉领域,涉及知识工程、自然语言处理、机器学习、图数据库等多个领域。而知识图谱的构建及应用涉及更多细分领域的一系列关键技术,包括:知识建模、关系抽取、图存储、自动推理、图谱表示学习、语义搜索、智能问答、图计算分析等。做好知识图谱需要系统掌握和应用这些分属多个领域的技术。
本书写作的第一个目的是尽可能地梳理和组织好这些知识点,帮助读者系统掌握相关技术,能够从整体、全局和系统的视角看待和应用知识图谱技术。早期的知识图谱应用主要是谷歌、百度等公司的通用域搜索引擎,以及基于搜索延续发展出来的基于知识图谱的智能问答应用,如天猫精灵、小米小爱等。这类应用主要依靠通用领域的知识图谱,如百科类知识图谱。近年来,知识图谱在医疗、金融、安全等垂直领域深入发展,知识图谱的应用也进一步从通用领域向越来越多的垂直领域扩展。对于刚刚进入该领域的从业人员,更需要能从应用入手,开展知识图谱的研究与开发。
本书写作的第二个目的是希望能够为这些知识图谱应用开发人员提供一本参考型的工具书。因此,本书在章节最后安排了一个小节介绍相关技术点的常用开源工具,并在与本书配套的网站上提供了完整的实际操作教程。
近几年,随着人工智能的进一步发展,知识图谱在深度知识抽取、表示学习与机器推理、基于知识的可解释性人工智能、图谱挖掘与图神经网络等领域取得了一系列新的进展。本书写作的第三个目的是希望梳理和整理这些与知识图谱相关领域的最新进展,帮助读者了解它们的技术发展前沿。
关于本书作者
本书邀请了国内从事相关领域研究和开发的一线专家。三位主编都在语义网和知识图谱领域有着十余年的研究和开发经验,同时也是中文领域开放知识图谱OpenKG的发起人。每个章节由各细分技术领域的专家主持撰写,参与编写的编者既有来自国内高校从事相关学术研究的教师,也有来自企业拥有丰富实际开发经验的技术专家。
本书主要内容
本书共包括9章,主要内容如下:
第1章主要介绍知识图谱的基本概念、历史渊源、典型的知识图谱项目、技术要素以及核心应用价值。
第2章围绕知识表示与建模,首先介绍传统人工智能领域的典型知识表示方法,如谓词逻辑、描述逻辑、框架系统等,接下来重点介绍RDF、OWL等互联网时代的知识表示框架,此外还介绍知识图谱的向量表示方法等。最后以Protégé为例介绍知识建模的具体实践过程。
第3章围绕知识存储,首先介绍知识图谱存储的主要特点和难点,然后介绍几种常用的知识图谱存储索引及存储技术,并对原生图数据库的技术原理进行简要介绍。此外,还概要介绍常用的图数据库,并以Apache Jena和gStore为例介绍知识图谱存储的具体实践过程。
第4章围绕知识抽取与知识挖掘,首先介绍从不同来源获取知识图谱数据的常用方法,然后重点围绕实体抽取、关系抽取和事件抽取等,对从文本中获取知识图谱数据的方法展开了较为具体的介绍。最后以DeepDive开源工具为例介绍关系抽取的具体实践过程。
第5章围绕知识图谱的融合,分别对概念层的融合和实体层的融合展开介绍,包括本体映射、语义映射技术、实体对齐、实体链接等。最后以LIMES开源工具为例介绍实体融合的具体实践过程。
第6章围绕知识图谱推理,首先介绍推理的基本概念,然后分别从基于演绎逻辑的知识图谱推理和基于归纳的知识图谱推理,对常用的知识图谱推理技术进行介绍。最后以Apache Jena和Drools等开源工具为例介绍知识图谱推理的具体实践过程。
第7章和第8章分别围绕语义搜索和知识问答展开,介绍语义索引、基于知识图谱的问答等系列技术,并以gAnswer等开源工具为例,介绍基于知识图谱实现精准搜索和问答的具体实践过程。
第9章为应用案例章节,作者挑选了电商、图情、生活娱乐、企业商业、创投、中医临床领域和金融证券行业7个应用案例,对知识图谱技术在不同领域的实现过程和应用方法展开介绍。
如何阅读本书
这是一本大厚书,读者应该怎样利用这本书呢?
在阅读此书前,读者应当学过数据库、机器学习及自然语言处理的基本知识。这本书的章节是依据知识图谱的相关技术点进行安排的。由于知识图谱涉及的技术面较多,我们建议刚进入知识图谱领域的读者分几遍阅读本书。
1)第一遍先通读全书,主要厘清基本概念,对涉及学术前沿的内容以及开源工具实践部分的内容可以只简单浏览。
2)第二遍重点针对每个章节后面的开源工具进行实践学习,通过上手操作加深对各技术点的理解。
3)第三遍针对各章中介绍的算法进行学习,并结合相关论文的阅读加深对算法的理解。在这个阶段可以挑选自己感兴趣的技术点进行深入研究。
在撰写本书时,编者考虑了各章节技术点的独立性,对知识图谱的某些技术已经有些了解的读者,可以不用严格按照书的章节顺序阅读,而是挑选自己感兴趣的章节进行学习。
致谢
本书是很多人共同努力的成果,在此感谢各位编者的共同努力。同时,在本书写作过程中,北京大学的邹磊,湖南大学的彭鹏,海知智能的袁熙昊、韩庐山、王燚鹏、孙胜男、郭玉婷,东南大学的吴桐桐、谭亦鸣、花云程、胡森,浙江大学的张文、王冠颖、王若旭、陈名杨、王梁、叶志权等人也提供了非常有价值的调研结果和修改意见,在此表示衷心的感谢。
在电子工业出版社博文视点宋亚东编辑的热情推动下,最终促成了我们与电子工业出版社的合作。在审稿过程中,他多次邀请专家对此书提出有益意见,对书稿的修改完善起到了重要作用。在此感谢电子工业出版社博文视点和宋亚东编辑对本书的重视,以及为本书出版所做的一切。
为推动中文领域开放知识图谱的发展,本书的作者们一致同意将部分稿酬捐赠给OpenKG。在此,也对参与本书的所有作者的无私奉献表示感谢。
由于作者水平有限,书中不足及错误之处在所难免。此外,由于知识图谱技术涉及面广,本书难免有所遗漏,敬请专家和读者给予批评指正。
作者
2019年7月
知识图谱的早期理念源于万维网之父Tim Berners-Lee关于语义网(The Semantic Web)的设想,旨在采用图结构(Graph Structure)来建模和记录世界万物之间的关联关系和知识,以便有效实现更加精准的对象级搜索。知识图谱的相关技术已经在搜索引擎、智能问答、语言理解、推荐计算、大数据决策分析等众多领域得到广泛的实际应用。近年来,随着自然语言处理、深度学习、图数据处理等众多领域的飞速发展,知识图谱在自动化知识获取、知识表示学习与推理、大规模图挖掘与分析等领域又取得了很多新进展。知识图谱已经成为实现认知层面的人工智能不可或缺的重要技术之一。
为什么写作本书
知识图谱是较为典型的交叉领域,涉及知识工程、自然语言处理、机器学习、图数据库等多个领域。而知识图谱的构建及应用涉及更多细分领域的一系列关键技术,包括:知识建模、关系抽取、图存储、自动推理、图谱表示学习、语义搜索、智能问答、图计算分析等。做好知识图谱需要系统掌握和应用这些分属多个领域的技术。
本书写作的第一个目的是尽可能地梳理和组织好这些知识点,帮助读者系统掌握相关技术,能够从整体、全局和系统的视角看待和应用知识图谱技术。早期的知识图谱应用主要是谷歌、百度等公司的通用域搜索引擎,以及基于搜索延续发展出来的基于知识图谱的智能问答应用,如天猫精灵、小米小爱等。这类应用主要依靠通用领域的知识图谱,如百科类知识图谱。近年来,知识图谱在医疗、金融、安全等垂直领域深入发展,知识图谱的应用也进一步从通用领域向越来越多的垂直领域扩展。对于刚刚进入该领域的从业人员,更需要能从应用入手,开展知识图谱的研究与开发。
本书写作的第二个目的是希望能够为这些知识图谱应用开发人员提供一本参考型的工具书。因此,本书在章节最后安排了一个小节介绍相关技术点的常用开源工具,并在与本书配套的网站上提供了完整的实际操作教程。
近几年,随着人工智能的进一步发展,知识图谱在深度知识抽取、表示学习与机器推理、基于知识的可解释性人工智能、图谱挖掘与图神经网络等领域取得了一系列新的进展。本书写作的第三个目的是希望梳理和整理这些与知识图谱相关领域的最新进展,帮助读者了解它们的技术发展前沿。
关于本书作者
本书邀请了国内从事相关领域研究和开发的一线专家。三位主编都在语义网和知识图谱领域有着十余年的研究和开发经验,同时也是中文领域开放知识图谱OpenKG的发起人。每个章节由各细分技术领域的专家主持撰写,参与编写的编者既有来自国内高校从事相关学术研究的教师,也有来自企业拥有丰富实际开发经验的技术专家。
本书主要内容
本书共包括9章,主要内容如下:
第1章主要介绍知识图谱的基本概念、历史渊源、典型的知识图谱项目、技术要素以及核心应用价值。
第2章围绕知识表示与建模,首先介绍传统人工智能领域的典型知识表示方法,如谓词逻辑、描述逻辑、框架系统等,接下来重点介绍RDF、OWL等互联网时代的知识表示框架,此外还介绍知识图谱的向量表示方法等。最后以Protégé为例介绍知识建模的具体实践过程。
第3章围绕知识存储,首先介绍知识图谱存储的主要特点和难点,然后介绍几种常用的知识图谱存储索引及存储技术,并对原生图数据库的技术原理进行简要介绍。此外,还概要介绍常用的图数据库,并以Apache Jena和gStore为例介绍知识图谱存储的具体实践过程。
第4章围绕知识抽取与知识挖掘,首先介绍从不同来源获取知识图谱数据的常用方法,然后重点围绕实体抽取、关系抽取和事件抽取等,对从文本中获取知识图谱数据的方法展开了较为具体的介绍。最后以DeepDive开源工具为例介绍关系抽取的具体实践过程。
第5章围绕知识图谱的融合,分别对概念层的融合和实体层的融合展开介绍,包括本体映射、语义映射技术、实体对齐、实体链接等。最后以LIMES开源工具为例介绍实体融合的具体实践过程。
第6章围绕知识图谱推理,首先介绍推理的基本概念,然后分别从基于演绎逻辑的知识图谱推理和基于归纳的知识图谱推理,对常用的知识图谱推理技术进行介绍。最后以Apache Jena和Drools等开源工具为例介绍知识图谱推理的具体实践过程。
第7章和第8章分别围绕语义搜索和知识问答展开,介绍语义索引、基于知识图谱的问答等系列技术,并以gAnswer等开源工具为例,介绍基于知识图谱实现精准搜索和问答的具体实践过程。
第9章为应用案例章节,作者挑选了电商、图情、生活娱乐、企业商业、创投、中医临床领域和金融证券行业7个应用案例,对知识图谱技术在不同领域的实现过程和应用方法展开介绍。
如何阅读本书
这是一本大厚书,读者应该怎样利用这本书呢?
在阅读此书前,读者应当学过数据库、机器学习及自然语言处理的基本知识。这本书的章节是依据知识图谱的相关技术点进行安排的。由于知识图谱涉及的技术面较多,我们建议刚进入知识图谱领域的读者分几遍阅读本书。
1)第一遍先通读全书,主要厘清基本概念,对涉及学术前沿的内容以及开源工具实践部分的内容可以只简单浏览。
2)第二遍重点针对每个章节后面的开源工具进行实践学习,通过上手操作加深对各技术点的理解。
3)第三遍针对各章中介绍的算法进行学习,并结合相关论文的阅读加深对算法的理解。在这个阶段可以挑选自己感兴趣的技术点进行深入研究。
在撰写本书时,编者考虑了各章节技术点的独立性,对知识图谱的某些技术已经有些了解的读者,可以不用严格按照书的章节顺序阅读,而是挑选自己感兴趣的章节进行学习。
致谢
本书是很多人共同努力的成果,在此感谢各位编者的共同努力。同时,在本书写作过程中,北京大学的邹磊,湖南大学的彭鹏,海知智能的袁熙昊、韩庐山、王燚鹏、孙胜男、郭玉婷,东南大学的吴桐桐、谭亦鸣、花云程、胡森,浙江大学的张文、王冠颖、王若旭、陈名杨、王梁、叶志权等人也提供了非常有价值的调研结果和修改意见,在此表示衷心的感谢。
在电子工业出版社博文视点宋亚东编辑的热情推动下,最终促成了我们与电子工业出版社的合作。在审稿过程中,他多次邀请专家对此书提出有益意见,对书稿的修改完善起到了重要作用。在此感谢电子工业出版社博文视点和宋亚东编辑对本书的重视,以及为本书出版所做的一切。
为推动中文领域开放知识图谱的发展,本书的作者们一致同意将部分稿酬捐赠给OpenKG。在此,也对参与本书的所有作者的无私奉献表示感谢。
由于作者水平有限,书中不足及错误之处在所难免。此外,由于知识图谱技术涉及面广,本书难免有所遗漏,敬请专家和读者给予批评指正。
作者
2019年7月
电子书版本
- Epub
图书类别
相关博文
-
AI进步的阶梯《知识图谱:方法、实践与应用》开启预售!
互联网促成了大数据的集聚,大数据进而促进了人工智能算法的进步。近年来知识图谱作为AI领域底层技术被越来越多的人谈起。知识图谱的升温得益于新数据和新算法为规模化知识图谱构建提供了新的技术基础和发展条件,使得知识图谱构建的来源、方法和技术...
922 0 0 0 -
分享实录丨阳德青教授分享“知识图谱起航”
知识图谱是实现机器人之智能的基础,也是一门应用广泛的工程学科。其具体方法大都来自计算机或人工智能的其他领域,比如自然语言处理、机器学习、知识工程等。面对如此庞杂的知识,初学者应该如何着手? 日前,我们邀请复旦大学大数据学院与大数据...
828 0 0 0


相关图书
DeepSeek应用大全:从入门到精通的全方位案例解析
本书以国产自研的强大AI模型DeepSeek为核心,系统呈现了DeepSeek从基础操作到各领域应用的32个实战案例,旨在帮助读者快速掌握DeepSeek的用法...
AI魔法绘画:用Stable Diffusion挑战无限可能
本书以实际操作为导向,详细讲解基于Stable Diffusion进行AI绘画的完整学习路线,包括绘画技巧、图片生成、提示词编写、ControlNet插件、模型...
知识图谱与认知智能:基本原理、关键技术、应用场景与解决方案
认知的高度决定了你创造价值的高度,包括你对世界的认知及世界对你的认知。知识图谱与认知智能技术的发展,既孕育了圈层变更的机会,也带来了人、机器、企业如何协同与博弈...
28-29页的内容是1.6.4节:知识图谱与推荐系统,这一节中多处描述中对应参考文献与描述对不上
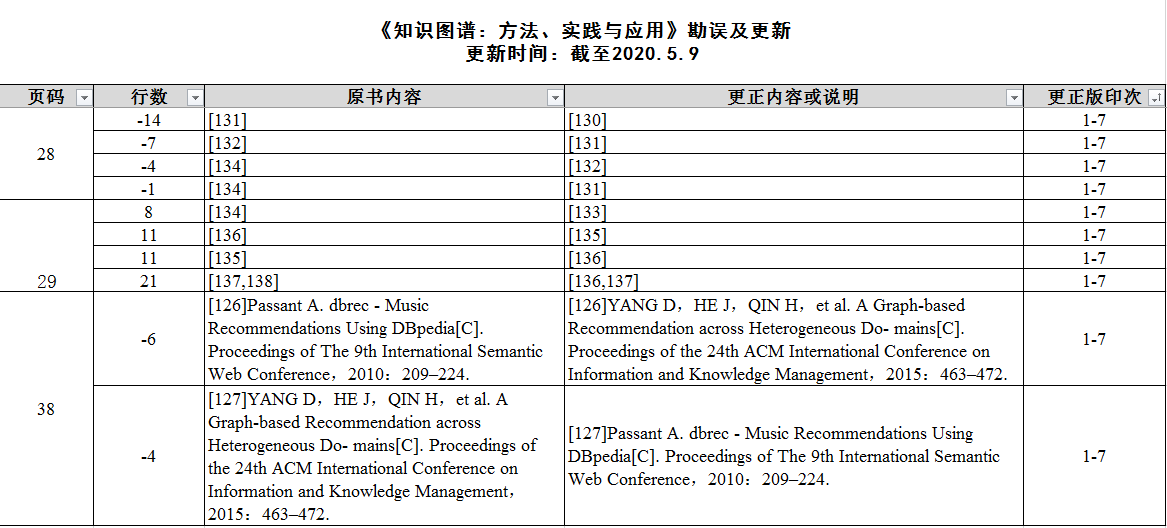
图1-2 从语义网络到知识图谱。Tim Berners-Lee提出四条链接规则是在2006年,图片中是1989年
参见链接https://www.w3.org/DesignIssues/LinkedData.html
[25]没有弄成上标
“…采用卷机神经网络进行链接预测”,应该是卷积神经网络
“表示知识的研究由来已有”改为由来已久