强化学习与有监督学习有什么区别?
随着 ChatGPT、Claude 等通用对话模型的成功,强化学习在自然语言处理领域获得了越来越多的关注。在深度学习中,有监督学习和强化学习不同,可以用旅行方式对二者进行更直观的对比,有监督学习和强化学习可以看作两种不同的旅行方式,每种旅行都有自己独特的风景、规则和探索方式。
• 旅行前的准备:数据来源
有监督学习:这如同旅行者拿着一本旅行指南书,其中明确标注了各个景点、餐厅和交通方式。在这里,数据来源就好比这本书,提供了清晰的问题和答案对。
强化学习:旅行者进入了一个陌生的城市,手上没有地图,没有指南。所知道的只是他们的初衷,例如找到城市中的一家餐厅或博物馆。这座未知的城市,正是强化学习中的数据来源,充满了探索的机会。
• 路途中的指引:反馈机制
有监督学习:在这座城市里,每当旅行者迷路或犹豫时,都会有人告诉他们是否走对了路。这就好比每次旅行者提供一个答案,有监督学习都会告诉他们是否正确。
强化学习:在另一座城市,没有人会直接告诉旅行者如何走。只会告诉他们结果是好还是坏。例如,走进了一家餐厅,吃完饭后才知道这家餐厅是否合适。需要通过多次尝试,逐渐学习和调整策略。
• 旅行的终点:目的地
有监督学习:在这座城市旅行的目的非常明确,掌握所有的答案,就像参观完旅行指南上提及的所有景点。
强化学习:在未知的城市,目标是学习如何在其中有效地行动,寻找最佳的路径,无论是寻找食物、住宿还是娱乐。
与有监督学习相比,强化学习能够给大语言模型带来哪些好处呢?针对这个问题,2023 年 4月 OpenAI 联合创始人 John Schulman 在 Berkeley EECS 会议上所做的报告“ReinforcementLearning from Human Feedback:Progress and Challenges”,分享了 OpenAI 在人类反馈的强化学习方面的进展,分析了有监督学习和强化学习各自存在的挑战。基于上述报告及相关讨论,强化学习在大语言模型上的重要作用可以概括为以下几个方面。
(1)强化学习相较于有监督学习更有可能考虑整体影响。有监督学习针对单个词元进行反馈,其目标是要求模型针对给定的输入给出确切的答案;而强化学习是针对整个输出文本进行反馈,并不针对特定的词元。反馈粒度的不同,使强化学习更适合大语言模型,既可以兼顾表达多样性,又可以增强对微小变化的敏感性。自然语言十分灵活,可以用多种不同的方式表达相同的语义。有监督学习很难支持上述学习方式,强化学习则可以允许模型给出不同的多样性表达。另外,有监督微调通常采用交叉熵损失作为损失函数,由于总和规则,造成这种损失对个别词元变化不敏感。改变个别词元只会对整体损失产生小的影响。但是,一个否定词可以完全改变文本的整体含义。强化学习则可以通过奖励函数同时兼顾多样性和微小变化敏感性两个方面。
(2)强化学习更容易解决幻觉问题。用户在大语言模型上主要有三类输入:(a)文本型(Text-Grounded),用户输入相关文本和问题,让模型基于所提供的文本生成答案(例如,“本文中提到的人名和地名有哪些”);(b)求知型(Knowledge-Seeking),用户仅提出问题,模型根据内在知识提供真实回答(例如,“流感的常见原因是什么”);(c)创造型(Creative),用户提供问题或说明,让模型进行创造性输出(例如,“写一个关于……的故事”)。有监督学习算法非常容易使得求知型查询产生幻觉。在模型并不包含或者知道答案的情况下,有监督训练仍然会促使模型给出答案。而使用强化学习方法,则可以通过定制奖励函数,将正确答案赋予非常高的分数,将放弃回答的答案赋予中低分数,将不正确的答案赋予非常高的负分,使得模型学会依赖内部知识选择放弃回答,从而在一定程度上缓解模型的幻觉问题。
(3)强化学习可以更好地解决多轮对话奖励累积问题。多轮对话能力是大语言模型重要的基础能力之一。多轮对话是否达成最终目标,需要考虑多次交互过程的整体情况,因此很难使用有监督学习的方法构建。而使用强化学习方法,可以通过构建奖励函数,根据整个对话的背景及连贯性对当前模型输出的优劣进行判断。
基于人类反馈的强化学习流程
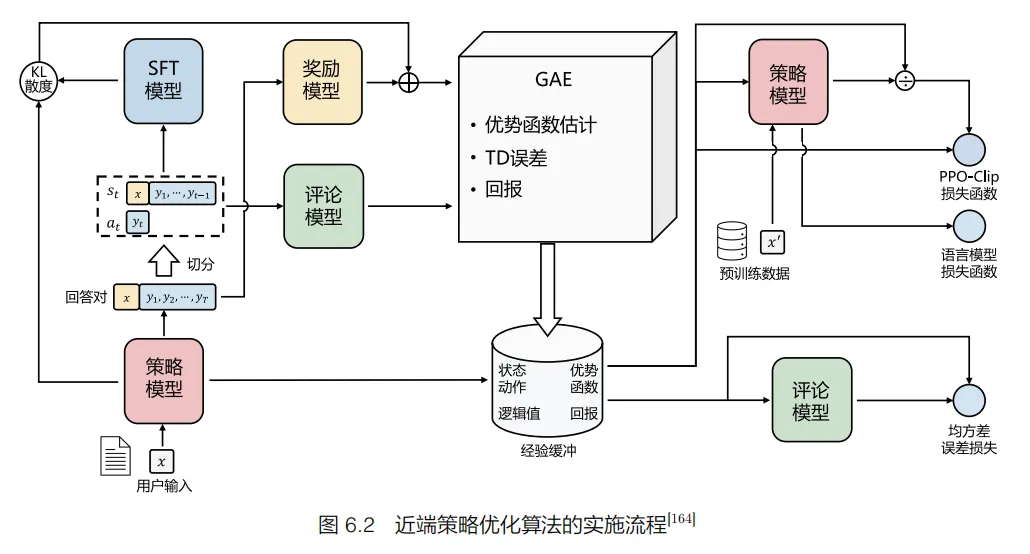
基于人类反馈的强化学习主要分为奖励模型训练和近端策略优化两个步骤。奖励模型通过由人类反馈标注的偏好数据来学习人类的偏好,判断模型回复的有用性,保证内容的无害性。奖励模型模拟了人类的偏好信息,能够不断地为模型的训练提供奖励信号。在获得奖励模型后,需要借助强化学习对语言模型继续进行微调。OpenAI 在大多数任务中使用的强化学习算法都是近端策略优化(Proximal Policy Optimization,PPO)算法。近端策略优化可以根据奖励模型获得的反馈优化模型,通过不断的迭代,让模型探索和发现更符合人类偏好的回复策略。近端策略优化算法的实施流程如图 6.2 所示。
近端策略优化涉及以下四个模型。
(1)策略模型(Policy Model),生成模型回复。
(2)奖励模型(Reward Model),输出奖励分数来评估回复质量的好坏。
(3)评论模型(Critic Model),预测回复的好坏,可以在训练过程中实时调整模型,选择对未来累积收益最大的行为。
(4)参考模型(Reference Model),提供了一个 SFT 模型的备份,使模型不会出现过于极端的变化。
近端策略优化算法的实施流程如下。
(1)环境采样:策略模型基于给定输入生成一系列的回复,奖励模型则对这些回复进行打分获得奖励。
(2)优势估计:利用评论模型预测生成回复的未来累积奖励,并借助广义优势估计(Generalized Advantage Estimation,GAE)算法估计优势函数,有助于更准确地评估每次行动的好处。
(3)优化调整:使用优势函数优化和调整策略模型,同时利用参考模型确保更新的策略不会有太大的变化,从而维持模型的稳定性。
为了使更多的自然语言处理研究人员和对大语言模型感兴趣的读者能够快速了解大模型的理论基础,并开展大模型实践,复旦大学张奇教授团队结合他们在自然语言处理领域的研究经验,以及分布式系统和并行计算的教学经验,在大模型实践和理论研究的过程中,历时8个月完成《大规模语言模型:从理论到实践》一书的撰写。希望这本书能够帮助读者快速入门大模型的研究和应用,并解决相关技术问题。
本书一经上市,便摘得京东新书日榜销售TOP1的桂冠,可想大家对本书的认可和支持!
这本书为什么如此受欢迎?它究竟讲了什么?下面就给大家详细~~
本书主要内容
本书围绕大语言模型构建的四个主要阶段——预训练、有监督微调、奖励建模和强化学习展开,详细介绍各阶段使用的算法、数据、难点及实践经验。
预训练阶段需要利用包含数千亿甚至数万亿单词的训练数据,并借助由数千块高性能GPU 和高速网络组成的超级计算机,花费数十天完成深度神经网络参数的训练。这一阶段的难点在于如何构建训练数据,以及如何高效地进行分布式训练。
有监督微调阶段利用少量高质量的数据集,其中包含用户输入的提示词和对应的理想输出结果。提示词可以是问题、闲聊对话、任务指令等多种形式和任务。这个阶段是从语言模型向对话模型转变的关键,其核心难点在于如何构建训练数据,包括训练数据内部多个任务之间的关系、训练数据与预训练之间的关系及训练数据的规模。
奖励建模阶段的目标是构建一个文本质量对比模型,用于对有监督微调模型对于同一个提示词给出的多个不同输出结果进行质量排序。这一阶段的难点在于如何限定奖励模型的应用范围及如何构建训练数据。
强化学习阶段,根据数十万提示词,利用前一阶段训练的奖励模型,对有监督微调模型对用户提示词补全结果的质量进行评估,与语言模型建模目标综合得到更好的效果。这一阶段的难点在于解决强化学习方法稳定性不高、超参数众多及模型收敛困难等问题。
除了大语言模型的构建,本书还介绍了大语言模型的应用和评估方法,主要内容包括如何将大语言模型与外部工具和知识源进行连接、如何利用大语言模型进行自动规划,完成复杂任务,以及针对大语言模型的各类评估方法。
本书目录
第1章 绪论 1
1.1 大语言模型的基本概念 1
1.2 大语言模型的发展历程 4
1.3 大语言模型的构建流程 8
1.4 本书的内容安排 11
第2章 大语言模型基础 13
2.1 Transformer结构 13
2.1.1 嵌入表示层 14
2.1.2 注意力层 16
2.1.3 前馈层 18
2.1.4 残差连接与层归一化 19
2.1.5 编码器和解码器结构 20
2.2 生成式预训练语言模型GPT 25
2.2.1 无监督预训练 26
2.2.2 有监督下游任务微调 27
2.2.3 基于HuggingFace的预训练语言模型实践 27
2.3 大语言模型的结构 33
2.3.1 LLaMA的模型结构 34
2.3.2 注意力机制优化 40
2.4 实践思考 47
第3章 大语言模型预训练数据 49
3.1 数据来源 49
3.1.1 通用数据 50
3.1.2 专业数据 51
3.2 数据处理 52
3.2.1 质量过滤 52
3.2.2 冗余去除 53
3.2.3 隐私消除 55
3.2.4 词元切分 55
3.3 数据影响分析 61
3.3.1 数据规模 61
3.3.2 数据质量 64
3.3.3 数据多样性 66
3.4 开源数据集 68
3.4.1 Pile 68
3.4.2 ROOTS 71
3.4.3 RefinedWeb 73
3.4.4 SlimPajama 75
3.5 实践思考 79
第4章 分布式训练 80
4.1 分布式训练概述 80
4.2 分布式训练的并行策略 83
4.2.1 数据并行 84
4.2.2 模型并行 88
4.2.3 混合并行 96
4.2.4 计算设备内存优化 97
4.3 分布式训练的集群架构 102
4.3.1 高性能计算集群的典型硬件组成 102
4.3.2 参数服务器架构 103
4.3.3 去中心化架构 104
4.4 DeepSpeed实践 110
4.4.1 基础概念 112
4.4.2 LLaMA分布式训练实践 115
4.5 实践思考 127
第5章 有监督微调 128
5.1 提示学习和语境学习 128
5.1.1 提示学习 128
5.1.2 语境学习 130
5.2 高效模型微调 131
5.2.1 LoRA 131
5.2.2 LoRA的变体 135
5.3 模型上下文窗口扩展 137
5.3.1 具有外推能力的位置编码 137
5.3.2 插值法 138
5.4 指令数据的构建 141
5.4.1 手动构建指令 141
5.4.2 自动构建指令 142
5.4.3 开源指令数据集 146
5.5 DeepSpeed-Chat SFT实践 147
5.5.1 代码结构 148
5.5.2 数据预处理 151
5.5.3 自定义模型 153
5.5.4 模型训练 155
5.5.5 模型推理 156
5.6 实践思考 157
第6章 强化学习 158
6.1 基于人类反馈的强化学习 158
6.1.1 强化学习概述 159
6.1.2 强化学习与有监督学习的区别 161
6.1.3 基于人类反馈的强化学习流程 162
6.2 奖励模型 163
6.2.1 数据收集 164
6.2.2 模型训练 166
6.2.3 开源数据 167
6.3 近端策略优化 168
6.3.1 策略梯度 168
6.3.2 广义优势估计 173
6.3.3 近端策略优化算法 175
6.4 MOSS-RLHF实践 180
6.4.1 奖励模型训练 180
6.4.2 PPO微调 181
6.5 实践思考 191
第7章 大语言模型应用 193
7.1 推理规划 193
7.1.1 思维链提示 193
7.1.2 由少至多提示 196
7.2 综合应用框架 197
7.2.1 LangChain框架核心模块 198
7.2.2 知识库问答系统实践 216
7.3 智能代理 219
7.3.1 智能代理的组成 219
7.3.2 智能代理的应用实例 221
7.4 多模态大语言模型 228
7.4.1 模型架构 229
7.4.2 数据收集与训练策略 232
7.4.3 多模态能力示例 236
7.5 大语言模型推理优化 238
7.5.1 FastServe框架 241
7.5.2 vLLM推理框架实践 242
7.6 实践思考 244
第8章 大语言模型评估 245
8.1 模型评估概述 245
8.2 大语言模型评估体系 247
8.2.1 知识与能力 247
8.2.2 伦理与安全 250
8.2.3 垂直领域评估 255
8.3 大语言模型评估方法 260
8.3.1 评估指标 260
8.3.2 评估方法 267
8.4 大语言模型评估实践 274
8.4.1 基础模型评估 274
8.4.2 SFT模型和RL模型评估 277
8.5 实践思考 282
参考文献 284
索引 303
作者介绍
相关专题
相关博文
-
用GPU进行TensorFlow计算加速
小编说:将深度学习应用到实际问题中,一个非常大的问题在于训练深度学习模型需要的计算量太大。为了加速训练过程,本文将介绍如何如何在TensorFlow中使用单个GPU进行计算加速,也将介绍生成TensorFlow会话(tf.Sessio...
5418 0 3 1 -
AI 大战高考作文!实测 ChatGPT、文心一言、通义千问等 8 款“神器”
2023 年高考作文题目火热出炉,其中全国甲卷作文题引人深思: 人们因技术发展得以更好地掌控时间,但也有人因此成了时间的仆人。 身处技术圈的我们,对于这句话可能有很多话想说。而对于这个话题,CSDN 也想问问近来大火的 AI 技术本...
672 0 0 0 -
提示工程七巧板:让ChatGPT发挥出最佳性能
机器有机器的作用,人有人的独特个性和价值。 正因为如此, 一方面,ChatGPT 等人工智能语言模型需要通过不断与人类的公共知识信息数据交互、汇聚,不断与人类进行对话,才能拥有越来越好的智能表现; 另一方面,作为人工智能机器...
215 0 0 0


读者评论