图技术是什么?一文详解大模型的认知引擎
图技术是指一切研究人类世界中事物和事物之间的关系,描述、刻画、分析和计算事物之间关系的技术,用于从图数据中挖掘出有价值的知识或规律来指导业务决策,如风险评估、事件溯源、因果推理和影响分析等。
图计算引擎(Graph Computing Engine)、图数据库和图可视化(Graph Visualization)是当下三个主要的图技术领域。
图计算引擎
早期,在专门针对图分析的计算机系统出现之前,业内主要通过单机图算法库或通用大数据计算系统来实现单机和集群环境下的图分析任务。
单机图算法库存在磁盘存储局限性,而通用大数据计算系统,如Google 推出的大规模数据并行处理计算模型 MapReduce,以及加利福尼亚大学伯克利分校(UC Berkeley)AMP Lab 开发的Spark 等,则存在一些性能、易用性等方面的问题。
随后,专业的图计算引擎诞生了。
图计算引擎基于内存中采用“顶点—边”的图数据模型,将计算应用于顶点和边,并提供了一组高效的算法实现和查询接口,让用户在大规模图数据上进行算法开发,执行计算与分析任务,并得到结果。
图计算引擎一般都是某种图计算框架的具体实现,如Apache Giraph、Apache Flink 等,也有一些独立的图计算引擎存在。
图计算框架提供图计算引擎理论模型的抽象设计,如定义计算迭代的编程模型、定义消息通信的同步模型,以及部分通用的参考实现。
2010 年,Google 在SIGMOD 会议上公开了 Pregel 系统,它是现代图计算框架的起源。
Pregel 系统遵循的整体同步并行计算模型,又称BSP(Bulk Synchronous Parallel)模型,是大规模图计算的重要基石,相当于图计算领域的MapReduce。
BSP模型把计算分为多个超步,每个超步分布式并行地执行多个子任务,汇总后再继续执行新的计算轮次,轮次之间用消息来协同信息。
BSP 在每个超步之间都要同步数据,可保证任务收敛性和结果正确性,但也会导致网络通信量大,计算资源耗费大。
高效的图分割算法可以优化超步间的消息传递,进而提升图算法性能。
因此出现了“点分割”“边分割”“混合切分”等图分割算法。
同年,卡内基梅隆大学推出了GraphLab图计算框架,提出了GAS(Gather-Apply-Scatter)异步计算模型,将每个计算步骤分为收集信息、归纳信息、对外输出新信息三个过程。
相比BSP 模型,GAS 模型通过划分计算阶段来提高灵活性和计算资源利用率,提高系统的并发处理能力,但也会牺牲部分任务的正确性。
Pregel 和GraphLab 对后续其他图计算引擎的设计产生了深远的影响,目前大部分图计算引擎的运算模型仍以BSP 模型和GAS 模型为主,常见的图计算引擎有Apache Spark 旗下的GraphX、源于Facebook 的Giraph、源于Alibaba的GraphScope 和源于Tencent 的Plato 等。
图数据库
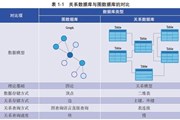
图数据库是以高效存储、查询、操作图数据为第一设计原理的数据库管理系统。
图数据库中的数据组织形式不再是传统关系数据库中由“行”和“列”组成的二维的表(Table)结构数据,而是以“顶点”和“边”为基础的数据存储单元:顶点与边分别表示对象以及对象之间的关系。
不同于关系数据库,关联关系在数据表之间以外键的形式隐性存在,必须通过连接(Join)操作从多张表中挖掘计算出来。
在图数据库中,关联关系,以“边”的形式显性存在,直接被存储与查询。
正是由于图数据库的底层数据模型能更自然、更直观地体现关系,因此它能更加高效地完成对现实生活中复杂业务逻辑与关联关系的处理。
关系数据库与图数据库的对比见表1-1。
相比于图计算引擎,图数据库能够实现图数据在存储介质上的持久化,这意味着图数据可以被反复查询、分析、迭代与分享,极大地扩展了图数据的应用场景。
因此,图数据库的发展对图技术行业的发展起到了重要的推动作用。
自2007 年第一款开源商用图数据库诞生以来,图数据库的发展虽然不过十余年,但在底层存储、架构等方面已经历了数次重大变革,由最初的单机图数据库向分布式大规模图数据库发展。
图技术的发展可以大致分为三个阶段,如图1-12 所示。
01. Graph 1.0:小规模原生图存储
在Graph 1.0 时代(2007—2010 年),早期的图应用领域聚焦在知识图谱、资产图谱、股权关系、血缘数据等分析型小数据场景,数据量相对静态且有限,顶点、边及其属性在图应用的生命周期内不会有大的变动或更改。
传统方案常以关系数据库作为存储,在内存或缓存层中实现图模型。
但是,当关系数据库通过多表连接实现关系查询时,查询耗时会随全局数据量的增加而呈指数级增长,即便在小数据场景中,查询性能也无法满足业务需求。
第一代真正意义上的图数据库以Neo4j 为代表,它开创性地实现了原生图数据库(Native Graph Database),即通过免索引邻接(Index-Free Adjacency)技术高效地实现了属性图的存储结构,无须额外索引,仅通过顶点的Key 即可直接找到所有与该顶点相连的边,使任何一个顶点都可以在常量时间内找到与之相连的邻居。
这样的技术实现决定了图查询的耗时仅与被查询顶点所关联的局部数据量相关,而不会如同传统方案那样随全局数据量的增长而增长。
然而,这个阶段的图存储在软件架构设计上仅支持单机部署或主备的集群模式,性能始终受单机资源限制,横向扩展能力不足。
02. Graph 2.0:分布式大规模图处理
在Graph 2.0 时代(2010—2016 年),随着大数据时代的到来,企业面临海量数据处理的痛点,系统的横向扩展能力成为业界刚需。
随着图数据规模的日渐扩大和图应用的逐步成熟,图分析应用开始从静态参考数据扩展到核心交易数据,如资金流向、信贷申请、消费及生产关系上,数据规模达到TB 级别。
此时,诞生了Titan(后更名为JanusGraph)、ArangoDB、HugeGraph 和NebulaGraph 等一系列分布式图数据库,它们在开源的分布式NoSQL 数据库(如HBase、RocksDB 等)上通过引擎层实现图数据语义处理。
这个阶段诞生的分布式图数据库解决了数据扩展性的问题,但由于底层存储层依然是基于键值数据库、列式数据库等在设计理念上并不以“关系”的表达和处理作为重点的其他数据库管理系统,所以,图遍历查询无法高效获得底层存储系统的支持,存在存储冗余多、加载耗时长、遍历查询内存耗费高等诸多问题。
因此,即便在同样的小规模数据上,其性能也往往落后于原生图数据库几个数量级。
03. Graph 3.0:原生分布式图存储
在Graph 3.0 时代(2016 年至今),图分析的价值得到了行业认可,其应用场景也被进一步拓展至企业运营的方方面面,逐步涵盖基于事件和行为的数据分析,如监管机构的反洗钱、电商平台的交易反欺诈、基于物联网IoT 数据的数字孪生、基于生产及物流记录的智慧供应链等。
因商业、生产、经营活动而产生的行为、事件数据,其规模轻易达到了TB 甚至PB 级别。
基于海量的实时数据做业务决策的优化,对底层数据库系统的大数据处理的结果实效性也提出了更高的要求。
为了解决上一代图数据库在大数据处理和查询时效间的矛盾,Graph 3.0 时代的图数据库不再依赖其他分布式存储系统,而是应用数据切割算法、分布式数据通信机制等技术,直接在原生图存储的基础上实现了系统的分布式架构,代表产品有Galaxybase、TigerGraph 等。
这一代图数据库不仅具备了良好的横向扩展性,还因为控制了底层的数据存储机制、实现了原生图存储,在大规模图数据的处理和查询性能上也有了大幅的提升。
总而言之,图数据库技术的发展是为了满足同时代的图应用对数据规模、查询计算性能、结果实时性的要求服务的。
其趋势背后是海量数据的复杂关联和实时决策需求,这推动着各行各业的数字化、智能化的不断进步。
目前,在行业参与者中,既有阿里巴巴、腾讯、蚂蚁、字节跳动、亚马逊、微软等全球公有云、软件服务、数据库等领域的巨头,也有Neo4j、TigerGraph、创邻科技等国内外商业化图数据库公司。
一方面,图数据库作为底层技术基础设施的一部分,巨头具备巨大的流量入口优势,同时拥有完整的数据库及大数据处理平台产品矩阵,极易通过捆绑销售实现自有产品的推广;另一方面,由于巨头产品线众多,其图数据库产品仍以服务内部业务需求为主,在项目实施、中小客户及行业客户的需求响应、定制化开发等方面能力不足,给商业化图数据库公司创造了竞争空间。
图可视化
图可视化技术泛指通过计算机图形学和图像处理等相关技术,将图数据转换为可视化图形并呈现给用户的技术。常用的图可视化技术包括以下内容。
顶点- 边图:将图中的顶点和边以点和线的形式表示,并使用不同的颜色、形状、大小等属性来表达顶点和边的特征,以便用户观察和分析。
矩阵图:将顶点和边表示为一个矩阵,其中每个单元格代表一对顶点之间的连通关系,并使用不同的颜色和阴影表达顶点和边的权重和特征。
布局算法:通过布局算法将顶点和边排列在一个平面上,以便用户观察和交互。常用的布局算法包括力导向布局、圆形布局和树形布局等。
时序图:将图中的数据按时间顺序绘制成一组图,以便用户观察和分析图数据随时间的变化和发展趋势。
三维图:将顶点和边呈现在三维空间中,并使用不同的颜色、形状、大小等属性来表达顶点和边的结构特征,以便用户观察和交互。
通过图可视化技术实现的可视化工具,可以帮助各领域的数据科学工作者更好地理解和分析图数据,通过简单的人机交互,探查图数据中潜在的模式、异常和趋势。
图可视化同样也是一种视觉的艺术形式,通过建模与渲染,凸显关键、有效的信息。
相比数字与文字,人类的大脑更善于感知处理图像信息:当一张密密麻麻满是数字的记录数百条交易流水的表格被可视化为账号之间的交易网络时,我们能更为迅速地理解众多账户间的交易关系;在使用可视化工具对分析页面进行缩放、扩展、布局等交互操作的过程中,我们也能更迅速地判断各类账户及交易行为的重要特征。
专业的图可视化产品需要克服并解决诸多技术难点,包括大图数据在浏览器端的高效渲染、有效的绘图布局、算法分析与检索加工处理等。
好的图可视化产品需要带有图分析和商业智能(BI)的功能,不仅涉及图中顶点和边的有效表达,还需帮助用户快速理解、统计、分析整体或局部的图结构。
市场上已有众多成熟的图可视化产品,Gephi 便是其中著名的一款。它可以实现大图数据的展示,进行复杂的图可视化配置,呈现丰富的可视化效果,如图1-13 所示。
完整的图分析(Graph Analytics)往往涉及上述三种图技术的综合运用:通过图数据库实现对图数据的高效查询,通过图计算引擎挖掘图数据的特征与模式,通过可视化工具实现查询与计算结果的展示与分析。三者相互关联,又各有不同(见表1-2)。
图数据库侧重支持OLTP(Online Transaction Processing)类的查询与增删查改等操作,支持动态数据的实时读写,对数据事务、一致性、实时处理能力要求较高。
图计算引擎则侧重OLAP(Online Analytical Processing)类的计算与挖掘,由于数据存储于内存中,一般不涉及数据的实时更改,所以它更适合需要全图迭代的图计算任务,通过批处理的方式执行,实时性要求低。
图可视化技术与图数据库、图计算引擎的区别在于:图可视化技术只负责图数据的可视化展示,既不持久化存储图数据,也无法对其进行复杂的计算。图可视化技术通过GUI(Graphical User Interface),以某种“点—边”的形式将给定的输入(Input)可视化展示出来,但输入的数据源可以来自图数据库或图计算引擎,也可以来自文本文件或其他关系数据库、非关系数据库。
在实际应用中,图数据库和图计算引擎的能力呈现融合趋势,图数据库企业正在将OLAP 能力与 OLTP 能力结合,向 HTAP 混合型数据库方向发展。部分头部厂商将三种技术结合,提供涵盖图数据存储、查询、计算、可视化分析等功能的一站式图平台(Graph Platform)。
本文选自《图数据库:理论与实践》一书,欢迎阅读此书了解更多图数据库相关内容。
相关专题
相关博文
-
超时与重试机制(2)—《亿级流量》
数据库客户端超时 在使用数据库客户端时,我们会使用数据库连接池,数据库连接池可以进行如下超时设置。 bean id="dataSource" class="org.apache.commons.dbcp...
1635 0 0 0 -
Binlog中的时间戳
小编说:本文从一个典型的案例入手来讲述Binlog中时间戳的原理和实践,通过本文你可以了解时间戳在Binlog中的作用及产生方法,以便在出现一些这方面怪异的问题时,做到心中有数,胸有成竹。本文选自《MySQL运维内参》 背景 众所周...
3572 0 0 0 -
聊聊Neo4j图数据库的那些明显优势
小编说:Neo4j是一个NoSQL的图数据库管理系统,像其他NoSQL数据库一样具有高效的查询性能。同时,Neo4j还具有完全事务管理特性,完全支持ACID事务管理。Neo4j与其他数据库相比,具有哪些明显的优势呢?本文选自《Neo4...
3882 0 0 0



读者评论