强化学习:DQN与Double DQN讨论
1 DQN方法
强化学习逐渐引起公众的注意要归功于谷歌的DeepMind公司。DeepMind公司最初是由Demis Hassabis, Shane Legg和Mustafa Suleyman于2010年创立的。创始人Hassabis有三重身份:游戏开发者,神经科学家以及人工智能创业者。Hassabis游戏开发者的身份使人不难理解DeepMind在Nature上发表的第一篇论文是以雅达利(atari)游戏为背景的。同时,Hassabis又是国际象棋高手,他在挑战完简单的雅达利游戏后再挑战深奥的围棋游戏也就不难理解了。这就有了AlphaGo和李世石的2016之战,以及他在Nature发表的第二篇论文。一战成名之后,深度强化学习再次博得世人的眼球。当然,DeepMind的成功离不开近几年取得突破进展的深度学习技术。本节主要讲解DQN,也就是DeepMind发表在Nature上的第一篇论文,名字是Human-level Control through Deep Reinforcement Learning。
平心而论,这篇论文只有两个创新点,即经验回放和设立单独的目标网络,后面我们会详细介绍。算法的大体框架是传统强化学习中的Qlearning。为了前后理解方便,我们简单梳理下。
Qlearning方法是异策略时间差分方法。其伪代码如图1所示。
掌握Qlearning方法一定要明白两个概念——异策略和时间差分,以及这两个概念在Qlearning算法是中如何体现的。下面我们一一介绍。
异策略,是指行动策略(产生数据的策略)和要评估的策略不是一个策略。在图1 的Qlearning 伪代码中,行动策略(产生数据的策略)是第5行的策略,而要评估和改进的策略是第6行的贪婪策略(每个状态取值函数最大的那个动作)。
时间差分方法,是指利用时间差分目标来更新当前行为值函数。在图1的 Qlearning伪代码中,时间差分目标为
Qlearning算法是1989年由Watkins提出来的,2015年Nature论文提到的DQN就是在Qlearning的基础上修改得到的。
DQN对Qlearning的修改主要体现在以下三个方面。
(1)DQN利用深度卷积神经网络逼近值函数;
(2)DQN利用了经验回放训练强化学习的学习过程;
(3)DQN独立设置了目标网络来单独处理时间差分算法中的TD偏差。
下面,我们对这三个方面做简要介绍。
(1)DQN利用卷积神经网络逼近行为值函数。
如图2所示为DQN的行为值函数逼近网络。与线性逼近不同,线性逼近指值函数由一组基函数和一组与之对应的参数相乘得到,值函数是参数的线性函数。而DQN的行为值函数利用神经网络逼近,属于非线性逼近。虽然逼近方法不同,但都属于参数逼近。请记住,此处的值函数对应着一组参数,在神经网络里参数是每层网络的权重,我们用θ表示。用公式表示的话值函数为Q(s,a;θ)。请留意,此时更新值函数时其实是更新参数θ,当网络结构确定时,θ就代表值函数。DQN所用的网络结构是三个卷积层加两个全连接层,整体框架如图2所示。
利用神经网络逼近值函数的做法在强化学习领域早就存在了,可以追溯到上个世纪90年代。当时学者们发现利用神经网络,尤其是深度神经网络逼近值函数不太靠谱,因为常常出现不稳定不收敛的情况,所以在这个方向上一直没有突破,直到DeepMind的出现。
我们要问,DeepMind到底做了什么?
别忘了DeepMind的创始人Hassabis是神经科学的博士。早在2005年,Hassabis就开始琢磨如何利用人的学习过程提升游戏的智能水平,为此他去伦敦大学开始攻读认知神经科学方向的博士,并很快有了突出成就,在Science、Nature等顶级期刊狂发论文。他当时的研究方向是海马体——那么,什么是海马体?为什么要选海马体?
海马体是人类大脑中负责记忆和学习的主要部分,从Hassabis学习认知神经科学的目的来看,他选海马体作为研究方向就是水到渠成的事儿了。
现在我们就可以回答,DeepMind到底做了什么?
他们将认识神经科学的成果应用到了深度神经网络的训练之中!
(2)DQN利用经验回放训练强化学习过程。
我们睡觉的时候,海马体会把一天的记忆重放给大脑皮层。利用这个启发机制,DeepMind团队的研究人员构造了一种神经网络的训练方法:经验回放。
通过经验回放为什么可以令神经网络的训练收敛且稳定?
原因是:训练神经网络时,存在的假设是训练数据是独立同分布的,但是通过强化学习采集的数据之间存在着关联性,利用这些数据进行顺序训练,神经网络当然不稳定。经验回放可以打破数据间的关联,如图3所示。
在强化学习过程中,智能体将数据存储到一个数据库中,再利用均匀随机采样的方法从数据库中抽取数据,然后利用抽取的数据训练神经网络。
这种经验回放的技巧可以打破数据之间的关联性,该技巧在2013年的NIPS已经发布了,2015年的Nature论文则进一步提出了目标网络的概念,以进一步降低数据间的关联性。
(3)DQN设置了目标网络来单独处理时间差分算法中的TD偏差。
与表格型的Qlearning算法(图1)不同的是,利用神经网络对值函数进行逼近时,值函数的更新步更新的是参数θ(如图4所示),DQN利用了卷积神经网络。其更新方法是梯度下降法。因此图1中第6行值函数更新实际上变成了监督学习的一次更新过程,其梯度下降法为
其中,为TD目标,在计算
值时用到的网络参数为θ。
我们称计算TD目标时所用的网络为TD网络。在DQN算法出现之前,利用神经网络逼近值函数时,计算TD目标的动作值函数所用的网络参数θ,与梯度计算中要逼近的值函数所用的网络参数相同,这样就容易导致数据间存在关联性,从而使训练不稳定。为了解决此问题,DeepMind提出计算TD目标的网络表示为θ-;计算值函数逼近的网络表示为θ;用于动作值函数逼近的网络每一步都更新,而用于计算TD目标的网络则是每个固定的步数更新一次。
因此值函数的更新变为
最后我们给出DQN的伪代码,如图5所示。
下面我们对DQN的伪代码逐行说明。
第[1]行,初始化回放记忆D,可容纳的数据条数为N;
第[2]行,利用随机权值θ初始化动作-行为值函数Q;
第[3]行,令θ-=θ初始化,计算TD目标的动作行为值Q;
第[4]行,循环每次事件;
第[5]行,初始化事件的第一个状态s1,通过预处理得到状态对应的特征输入;
第[6]行,循环每个事件的每一步;
第[7]行,利用概率ε选一个随机动作at;
第[8]行,若小概率事件没发生,则用贪婪策略选择当前值函数最大的那个动作
注意:这里选最大动作时用到的值函数网络与逼近值函数所用的网络是一个网络,都对应θ。
注意:第[7]行和第[8]行是行动策略,即
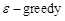
第[9]行,在仿真器中执行动作at,观测回报rt以及图像xt+1;
第[10]行,设置
预处理
第[11]行,将转换储存在回放记忆D中;
第[12]行,从回放记忆D中均匀随机采样一个转换样本数据,用
第[13]行,判断是否是一个事件的终止状态,若是则TD目标为rj ,否则利用TD目标网络θ-计算TD目标
第[14]行,执行一次梯度下降算法
第[15]行,更新动作值函数逼近的网络参数
第[16]行,每隔C步更新一次TD目标网络权值,即令θ-=θ;
第[17]行,结束每次事件内循环;
第[18]行,结束事件间循环。
我们可以看到,在第[12]行利用了经验回放;在第[13]行利用了独立的目标网络θ-;第[15]行更新动作值函数逼近网络参数;第[17]行更新目标网络参数。
2 Double DQN
上面我们讲了第一个深度强化学习方法DQN,DQN的框架仍然是Qlearning。DQN只是利用了卷积神经网络表示动作值函数,并利用了经验回放和单独设立目标网络这两个技巧。DQN无法克服Qlearning 本身所固有的缺点——过估计。
那么什么是过估计?Qlearning为何具有过估计的缺点呢?
过估计是指估计的值函数比真实值函数要大。一般来说,Qlearning之所以存在过估计的问题,根源在于Qlearning中的最大化操作。
Qlearning评估值函数的数学公式如下有两类。
对于表格型,值函数评估的更新公式为
对于基于函数逼近的方法的值函数更新公式为
从以上两个式子我们知道,不管是表格型还是基于函数逼近的方法,值函数的更新公式中都有max操作。
max操作使得估计的值函数比值函数的真实值大。如果值函数每一点的值都被过估计了相同的幅度,即过估计量是均匀的,那么由于最优策略是贪婪策略,即找到最大的值函数所对应的动作,这时候最优策略是保持不变的。也就是说,在这种情况下,即使值函数被过估计了,也不影响最优的策略。强化学习的目标是找到最优的策略,而不是要得到值函数,所以这时候就算是值函数被过估计了,最终也不影响我们解决问题。然而,在实际情况中,过估计量并非是均匀的,因此值函数的过估计会影响最终的策略决策,从而导致最终的策略并非最优,而只是次优。
为了解决值函数过估计的问题,Hasselt提出了Double Qlearning的方法。所谓Double Qlearning 是将动作的选择和动作的评估分别用不同的值函数来实现。
那么,什么是动作的选择?什么是动作的评估?感兴趣的同学可以在《深入浅出强化学习:原理入门》一书中了解更多。
相关专题
相关博文
-
强化学习是如何解决问题的?
什么是强化学习算法呢,它离我们有多远?2016年和2017年最具影响力的AlphaGo大胜世界围棋冠军李世石和柯洁事件,其核心算法就用到了强化学习算法。相信很多人想了解或者转行研究强化学习算法或多或少都跟这两场赛事有联系。如今,强化学习...
2563 0 1 0

读者评论