看Python大采集术如何搞定15000+部漫画信息
你是否有这样的问题,学 Python 语言之后,能做什么?
Python的用途其实非常多,今天先来展示一个用Python采集漫画信息的实操案例。
01 目标站点数据源分析
▊ 爬去目标
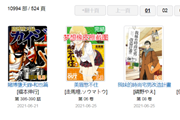
本次要爬取的网站是一个漫画网站,打开站点,呈现在我们面前的是 15660 部漫画信息,我们的目标是全部“拿下”。
为了降低学习难度,本文只介绍针对列表页进行抓取的过程,里面涉及的目标数据结构如下。
漫画标题
漫画评分
漫画详情页链接
作者
同时,在案例代码中需要同步保存漫画封面,并以封面文件名为漫画命名。
漫画详情页还存在大量的标签,因不涉及数据分析,故不再提取。
▊ 涉及的Python模块
爬取模块requests,数据提取模块re,多线程模块 threading。
▊ 重点学习内容
爬虫编写流程。
数据提取,重点掌握行内 CSS 提取。
CSV 格式文件存储。
变换IP 规避反爬,该目标网站有反爬机制。
▊ 列表页分析
通过点击测试,得到的页码变化逻辑如下。
页面数据是服务器直接静态返回的,加载到 HTML 页面中。
目标数据所在的 HTML DOM 结构如下所示。
▊ 匹配封面图
在编写该部分正则表达式时,出现了下图所示的“折行+括号”问题。
正则表达式如下,这里重点需要注意 \s 可匹配换行符。
▊ 匹配文章标题、作者、详情页地址
该部分内容所在的 DOM 行格式比较特殊,可以直接匹配出结果。下述正则表达式使用了分组命名的方法。
02 整理出的需求
整理需求如下。
开启 5 个线程对数据进行爬取。
保存所有的网页源码。
依次读取源码,提取元素到 CSV 文件中。
本案例将优先保存网页源码到本地,然后对本地 HTML 文件进行处理。
03 编码时间
在编码测试的过程中,我们发现该网站存在反爬措施,会直接封杀爬虫程序的IP,导致程序还没有跑起来,就结束了。
再次测试,发现反爬技术使用重定向操作,即服务器发现是爬虫后,直接返回状态码 302,并重定向谷歌网站。
IP受限制的时间大概是 24 个小时,因此如果希望爬取到全部数据,需要通过不断切换 IP 和 UA ,将 HTML 静态文件保存到本地。
下述代码可以判断目标网站返回的状态码,如果为 302,则更换代理 IP,再次爬取。
只开启了 5 个线程,爬取过程如下所示。
经过 20 多分钟的等待,524 页数据全部以静态页形式保存在了本地 HTML 文件夹中。
当文件全部存储到本地之后,再进行数据提取就非常简单了。编写如下提取代码,使用 os 模块。
代码提取到 csv 文件如下所示。
关于详情页,即动漫的更新信息,可以使用上述逻辑再次爬取。
04 总结
完全学会本文中的操作,不仅需要用到 Python 的基础知识,还要掌握Python requests 模块、正则模块 re 、文件读写、多线程模块的相关内容。
想要快速学习这些内容,可以从阅读《滚雪球学Python》这本书开始。
滚雪球学 Python,书如其名,教授大家用类似滚雪球的思维学习 Python,第一遍浏览 Python 核心内容,第二遍补齐周边知识,第三遍夯实,第四遍拔高。每一遍滚雪球式的学习,都能丰富自己的知识。
相关专题
相关博文
-
(三)spring cloud云服务架构代码结构详细讲解
上一篇我们介绍了spring cloud云服务架构 - particle云架构代码结构,简单的按照几个大的部分去构建代码模块,让我们来回顾一下: 第一部分: 针对于普通服务的基础框架封装(entity、dao、service、co...
1413 1 4 4 -
Spring Cloud构建微服务架构—配置中心
Spring Cloud Config是Spring Cloud团队创建的一个全新项目,用来为分布式系统中的基础设施和微服务应用提供集中化的外部配置支持,它分为服务端与客户端两个部分。其中服务端也称为分布式配置中心,它是一个独立的微服务...
654 2 2 2 -
Spring Cloud构建微服务架构—服务容错保护(Hystrix服务降级)
在开始使用Spring Cloud Hystrix实现断路器之前,我们先拿之前实现的一些内容作为基础,其中包括: eureka-server工程:服务注册中心,端口:1001 eureka-client工程:服务提供者,两个实例启动...
594 2 2 2
读者评论