第三章,采用rennet_v1_50模型进行训练,已经训练完成,想导出模型对单张图像进行识别,最后的classfy_image_inception_v3.py出现错误,应该怎么修改呀? KeyError: “The name ‘resnet_v1/logits/SpatialSqueeze:0’ refers to a Tensor which does not exist. The operation, ‘resnet_v1/logits/SpatialSqueeze’, does not exist in the graph.”
第三章,采用rennet_v1_50模型进行训练,已经训练完成,想导出模型对单张图像进行识别,最后的classfy_image_inception_v3.py出现错误,应该怎么修改呀?
KeyError: “The name ‘resnet_v1/logits/SpatialSqueeze:0’ refers to a Tensor which does not exist. The operation, ‘resnet_v1/logits/SpatialSqueeze’, does not exist in the graph.”
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[3136,1024] and type float on /job:localhost/replica:0/task:0/device 0 by allocator GPU_0_bfc
0 by allocator GPU_0_bfc 0”]]
0”]]
[Node: Variable_4/Adam_1/Assign = Assign[T=DT_FLOAT, _class=[“loc:@Variable_4”], use_locking=true, validate_shape=true, _device=”/job:localhost/replica:0/task:0/device
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
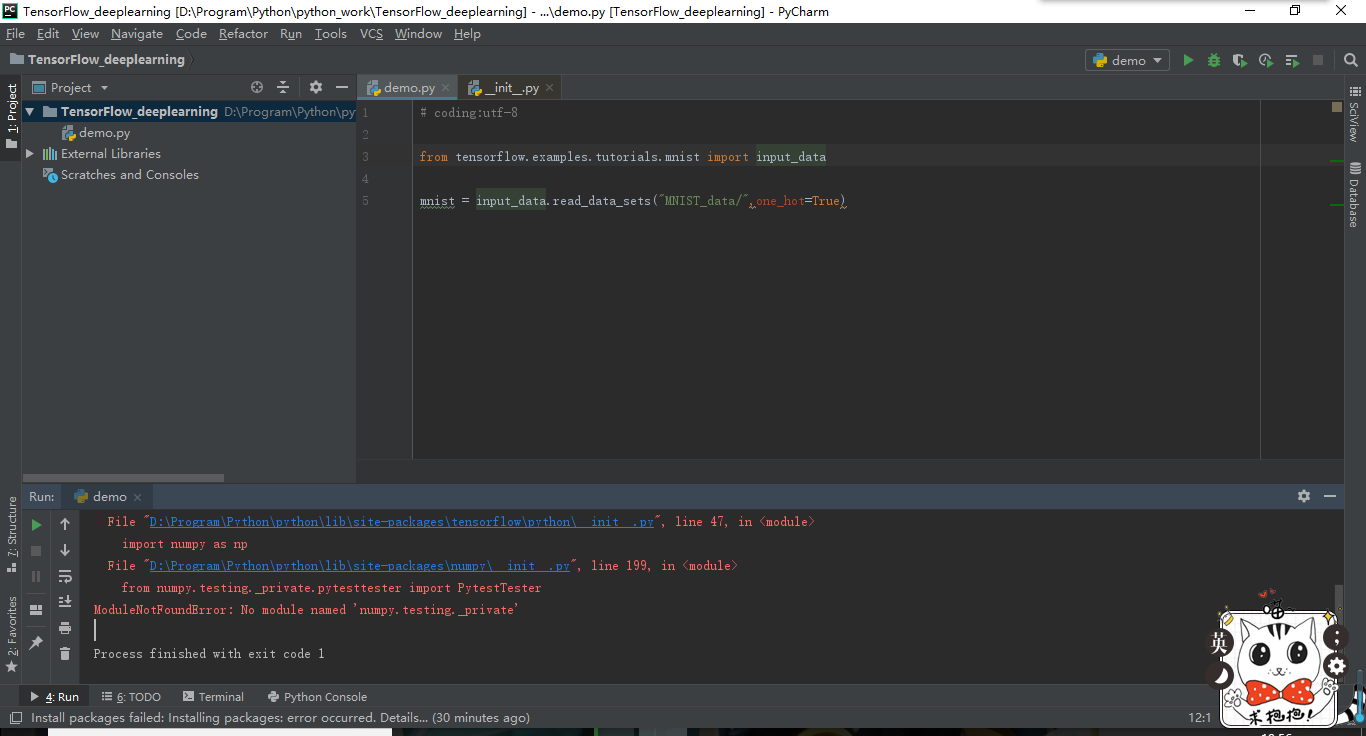
第一章 volutional.py出现这个错误
第五章 运行
python train.py —train_dir voc/train_dir/ —pipeline_config_path voc/voc.config
报错
TypeError: Cannot convert a list containing a tensor of dtype <dtype: 'int32'> to <dtype: 'float32'> (Tensor is: <tf.Tensor 'Preprocessor/stack_1:0' shape=(1, 3) dtype=int32>)
conv1
with tf.variable_scope(‘conv1’) as scope:
kernel = _variable_with_weight_decay(‘weights’,
shape=[5, 5, 3, 64],
stddev=5e-2,
wd=0.0)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding=’SAME’)
biases = _variable_on_cpu(‘biases’, [64], tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(pre_activation, name=scope.name)
_activation_summary(conv1)
pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding=’SAME’, name=’pool1’)
norm1
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name=’norm1’)
第一段代码就出错,求大佬教学